Weekly AI Agent News!から見えたAIエージェントの現在地
こんにちは!もう12月ということで一年の締めくくりの記事を書きます。 第一弾ではWeekly AI Agent News!を4月から更新し続けた学びを書きます。 様々なエージェントの論文から技術的な気づきとWeekly AI Agents News!を更新し続けて良かったことをそれぞれ紹介します。
第二弾の記事は、AIエージェントのビジネスの現状と今後の考察です。
こちらも是非!
AIエージェントビジネスの現状と今後の考察 - 襖からキリン
weekly AI Agents News! は私が会社と関係なく個人的に始めたエージェントに関する論文やニュースをまとめた資料です。 4月から2週に1度更新をしており、AIのビジネスを考える層やエージェントを開発するLLMエンジニア層、AI研究者層をターゲットに情報を発信しています。 過去のものアーカイブされています。
最近リポジトリでも論文を整理しました。併せてご覧ください!
なぜ資料の更新をしていたのか
直接的な金銭をもらっているわけでもなく、なぜ無料で継続して更新していたのかを説明します。 一番は自分の学びのためです。その次にエージェントの面白さを1人でも多くの方に知ってほしいという思いです。
まずエージェントは設計からチューニングまで面白いです。 エージェントはLLM単体で完結せず、業務アプリやシステムとAPIやコード経由で接続し、実行履歴をメモリで管理しながらタスクを実行します。 人間のためのソフトウェアやシステム、ドキュメントをAIが活用して問題解決するのは今までにないエージェントの醍醐味です。 そして、なるべく多くの問題解決をできるようにAIの思考回路を汎用的に作り込むのは難しくもAGIへの道となり、エンジニアリングが非常にものを言います。 人間ならどう考え、新人ならベテランならどうするか、合理的に考えればどうあるべきか、と考えながらエージェントの思考回路を作るのはやりがいの一つです。
今までの微調整したモデルをAPIにして継続的に改善していくのも十分楽しいですが、よりガチャガチャとパーツを組み替えながら作っていくエージェント開発が私は楽しいです。 余談ですが、エージェントは大学の研究室より企業の方が取り組みやすく相性は良いと考えています。企業は様々なソリューションを持ち、独自データがあります。 これらを活用したエージェントがどのような顧客体験を提供できるのか考え、PoCをするのはワクワクしますね。
そんなエージェントの面白さを1人でも多くの人に知ってもらいたく発信を始めました。発信を始めた2024年春頃はRAGかLLM開発が世間の注目を集めていたと認識しています。 国内の優秀な方はLLMの開発に取り組まれ、LLMを応用したエージェントを開発する人材は少なく、会社外で議論できる人が少なかったです。(取り組んでそうな方とはDMして直接会話してました。) また私が社内でエージェントを取り組んでいても、自部署と私と対話した顧客くらいにしかエージェントの面白さが伝わりません。 多くの方がエージェントに興味を持って国内でエージェントの取り組みが増えて盛り上がれば嬉しいくらいの気持ちで始めました。(と言いつつビッグテック企業がエージェントをリリースし始めれば日本の企業も後追いするのはほぼ自明なので、先に技術に明るい人に伝わればいいのと、後追いする人の知の高速道路になればいいなという気持ちもありました。)
そのため、発信する内容には論文では応用面と基礎面を分けました。結局、エージェントの応用先が金になりそうでなければ誰も取り組まないので、どんな応用があるのかは大事です。 そして、基礎面では応用があっても精度が低ければ意味がないので、エージェントの基礎技術の精度向上方法やその精度をまとめました。 プロダクトやニュースではベンチャーのプロダクトにコンサルやブログなど様々な媒体でエージェントに関するものを集め動向を注視しできるようにしました。
技術的に気づいたこと3選
1) マクロレベルでエージェントアーキテクチャに差分はない
昨今のLLMを用いたエージェントは登場から2年近く経っていますが、2024年に何か新しいエージェントの基礎技術があったかといわれると言葉が詰まります。 エージェントの基礎は2023年の夏には出揃っていたと思います。 エージェントの基礎は、知覚、プロフィール、プランニング、リフレクション、ツール利用、メモリです。 各大学や企業が様々なエージェントアーキテクチャを提案したのも2024年の特徴ですが、どれも同じ基礎技術を使っています。 もう少し言うと、エージェントアーキテクチャもほぼ同じです。過去の経験をメモリから引き出して、計画して、行動して、振り返って、目標を達成したか確認するプロセスはどのエージェントも同じです。
例えば、ソフトウェアを操作するエージェントを見てみます。
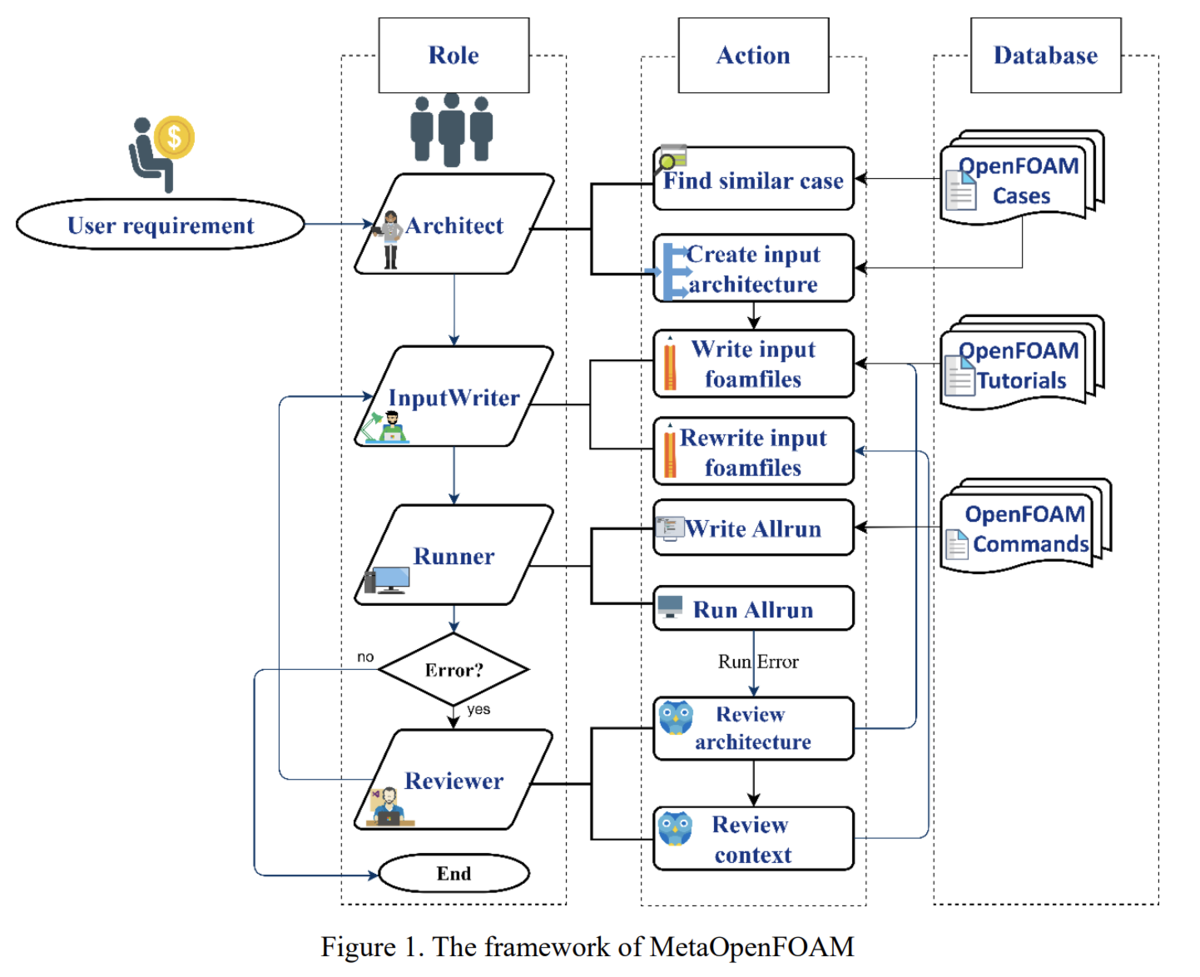
- 一つ目は、流体解析のソフトウェア(OpenFOAM)のチュートリアルや操作コマンドをもとにエージェントが実行する論文です。
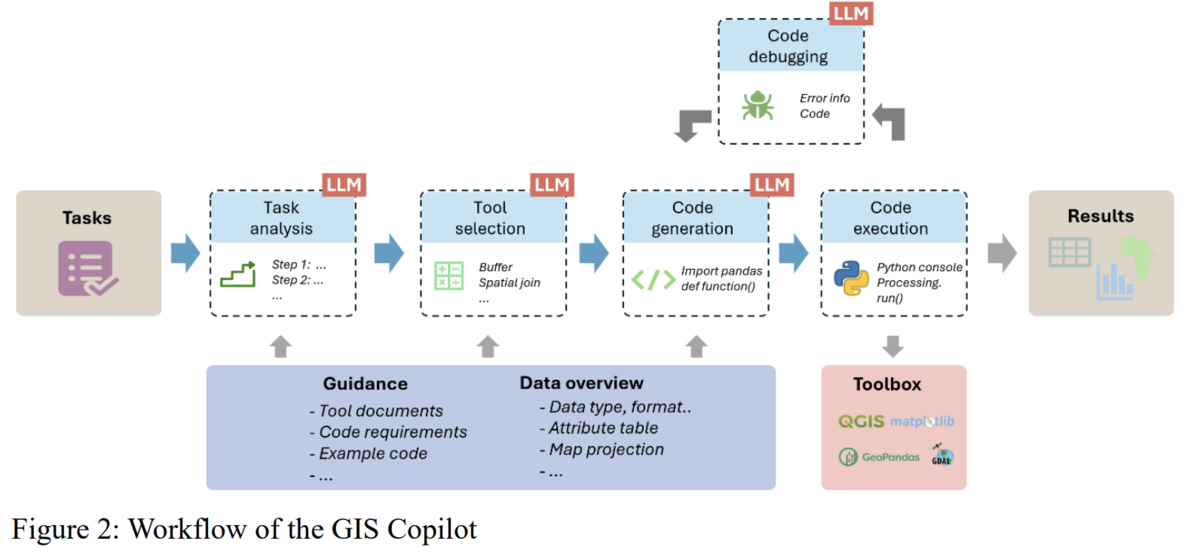
- 二つ目は、地理空間情報データ分析のソフトウェア(QGIS)の操作を自動化するエージェントの論文です。
どちらもエージェントのアーキテクチャの根幹は同じです。図を見ると人間の役割をもとに業務プロセスを記述するか、エージェントのワークフローを記述するかの違いです。
ソフトウェアの操作だけでなく、RAGの拡張も、データ分析も文章作成系もマクロレベルでは同様なエージェントアーキテクチャになっていることがほとんどです。
なぜならそれが人間の基本的な思考と行動プロセスだからです。考えて、行動して、振り返って、また考えて、行動する。
エージェントの細部を作りこむことは怠らない
アーキテクチャに差分がなければ、どこに違いがあって2024年は研究は進んだのでしょうか、または精度に差を出したのでしょうか。 それは問題設定を定義し直すか、エージェントの細部にこだわるかです。
エージェントの細部の一つは基礎モジュールの高度化です。 メモリを作り込むか、ツールを作り込むか、知覚内容を簡潔にするか、プランニングを階層化するか、特定の用途で学習するかなど、基礎部分の高度化で差分を出します。
もう一つの細部はプロンプトエンジニアリングです。 メモリに保存する内容の抽出プロンプトだったり、ツールを選択する基準であったり、プランニングの方向性を縛るプロンプトだったりします。
これらのトレードオフとして、解ける問題が狭まったり、推論時間が増えたり、コストが増えたり、メモリ管理が問題になったりしています。
自社で取り組むエージェント開発に役立ちそうなテクニックを知りたい方は、Weekly AI Agent News!を読んで頂ければと思います。
2) 2024年のAIエージェントは応用の開拓の年だった
応用の開拓の年と思えた一つに2024年は多くのベンチマークが用意されエージェントが評価されました。 ベンチマークのジャンルは応用系だとコンピュータ操作、データ分析&モデリング、リスク評価、ソフトウェア開発です。 またエージェントの個別能力のツール利用力や計画力などを評価するベンチマークも多数ありました。 ベンチマークは徐々に問題設定が現実的になり、オフラインからオンライン評価に変わり、過去のベンチマークを見直す動きがありました。 これらのベンチマークの評価からエージェントの限界や特徴を抑えるのは意味があります。 皆さんが先行研究で明らかになっている課題で躓かないように、ベンチマークの詳細、実験設定と結果、エラー分析は今後も目を通しておくことをお勧めします。
もう一つ応用開拓の年と思えたのは、特定の業務に向けたエージェントを開発し評価した論文が多く発表されたからです。 これらはコンピュータ操作のように多くの企業が競い合って取り組む系統と違い、ニッチな業務でエージェントを開発して適応してみたという研究で、AIコンサルのようなビジネスサイドはそういった論文の方が興味があると思います。 例えば以下のような研究があります。
- Salesforce はCRMの業務を代替するエージェント用のベンチマークを提案しています(Huang, 2024)。Salesforce AI Research はエージェントに力入れてますね。よく論文を見かけます。 自社の強みを活かしてエージェントで顧客体験を改善していくのはどうでしょうか。
- Siemens は製造現場の製造計画やプロセス評価のための3Dモデリングを自動化するエージェントを提案しています(Xia, 2024)。Siemensが提供するTecnomatixのAPIを利用します。 製造業にありがちな複雑なソフトウェアの操作やアイデア出しにつながるのではないでしょうか。
- Microsoftと香港大学はテーブルデータからレポートを作成するエージェントを提案しています(Shen, 2024)。グラフとその説明だけでなく、レポートの読み方のストーリーまで作ります。 レポート作成が多い部署の支援になるのではないでしょうか。
- 教育系だと精華大学らがメンターエージェントを提案しています。(Zha, 2024)。学生が問題発見から情報収集、解決策を考える思考能力を身につくように手助けします。 教育系のビジネスをする方の支援になるのではないでしょうか。


2025年は日本でも多くの企業がエージェントを取り組むと予想されます。 最初はRAGのときと同様で成功しそうな先行事例のある問題設定で取り組み、知見を得るフェーズです。 関係者の知見も溜まれば、次は自社の業務特有の深い課題に挑戦していき、エージェントの応用が業界単位で枝分かれしていくと予想します。
応用を他に知りたい方は私のリポジトリにまとめているのでご覧ください!
GitHub - masamasa59/ai-agent-papers: Weekly AI Agent News!の論文内容を更新
3) エージェントを独自開発して本当に精度は向上しているのか
多くの企業や組織が既存エージェントをカスタマイズするのではなく、エージェントアーキテクチャから開発して、知見を溜めている段階です。 しかし、論文を読む中でエージェントに懐疑的に思うことがあるので共有します。
一つ目は、車輪の再発明とまでは言いませんが、新たに論文で〇〇 Agent を提案しても、結果から明らかになったことも、課題も半年前から分かっていたことで、精度もそこまで改善していないのではないのか。 多くの論文が似たような問題設定で似たようなエージェントを作って、同じ課題にぶつかっていると感じます。 まるでCNNやLSTMの亜種モデルを作っていた頃のようです。 少し違うのはNNモデルのときと違い、個別にエージェントを開発しすぎて正当な比較ができていないのがエージェント界隈の課題です。 エージェントが観測する内容やその前処理方法、行動内容など様々な違いがあり、ベンチマークもそれぞれが作り、比較するのは難しくなっています。 研究での評価は、開発したエージェントのLLMを変えて比較したり、開発したエージェントの一部の機能を取り除いて評価したり、競争力があまりないシンプルなエージェントで比較しているのが実情です。 本当に開発したエージェントは別のより価値があるのか謎になっています。
二つ目は、エージェントの開発に見合う精度がでているのかが疑問です。
LangChainが1300名に取ったアンケートでも、エージェントの精度が重要だと報告されています。

OS Worldのベンチマークで比較をすると精度の高いエージェントで20%台です。20%と数字が低いことは残念ですがそこが問題ではありません。他の最近のエージェント論文でもOSCAR (Wang, 2024)で24.5%、OS-ATLAS (Wu, 2024)で14.63%、LMM単体と比べれば10%程度の改善はありますが、エージェント間ではどんぐりの背比べになっています。 この10%を大幅な改善として見るかは人によりますが、私は開発と保守工数に対して、中々厳しい結果だと受け止めています。 なぜなら従来のNNの損失関数の工夫や層数やアテンション方法と違い、エージェントはマクロレベルではアーキテクチャは似ていますが、細部でLLMの観測内容、行動の選択肢、計画方法と様々な部分で違いを作っています(コード量もプロンプトもそれなりに多い)。 しかし、異なるエージェントとの差、ベースモデルとの差が最終性能で見たときに数%のインパクトしか与えていないということです。
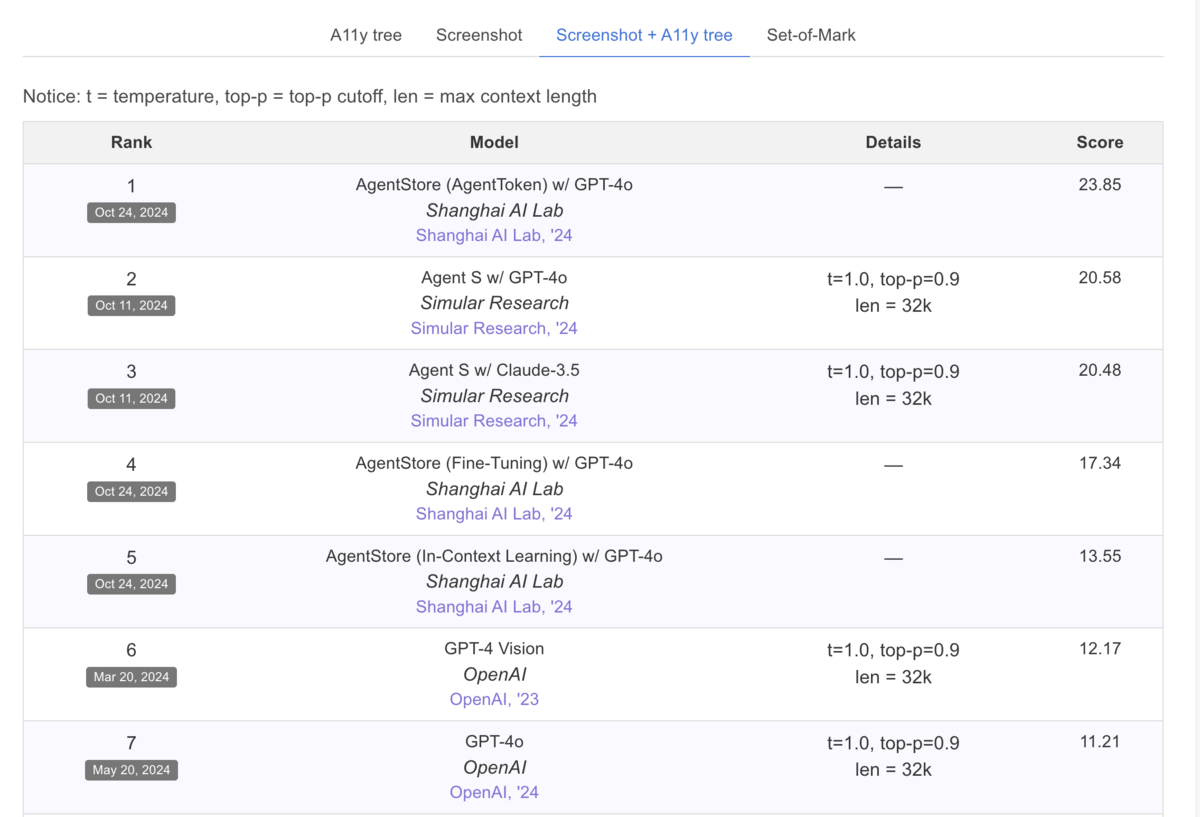
もう一つVisualWebArenaのLeaderboardを見てみます。
ベースのGPT4oからどれだけエージェントの仕組みを入れて精度が向上しているか見てみます。
ここでもエージェントの最高性能でgpt4oに比べ13.92%アップしていますが、それ以外のエージェントたちは数%の改善幅で並んでおり、元のLLMの能力の限界に強く引きづられ、峠を越えるようなインパクトのある結果にはなっていません。
個人的にエージェントになったからにはLLM単体から数メートル先で着地しないでほしいという気持ちがあります。

最後にエージェントアーキテクチャの自動探索の研究結果を見てみます。
複数の初期のエージェントアーキテクチャから改良を加えていく方法ですが、有名なADAS(Hu, 2024) の結果を含めた最新の自動探索手法 AFlowの結果を見てみます(Zhang, 2024)。

単純なgpt4o-miniと比較して、アーキテクチャの自動探索結果は7.5%しか向上していません。ADASに限っては意図的かはさておき、gpt-4o-mini単体より低い結果を示しています。 また有名なプロンプト手法と比較しても、数%の違いしか生み出せていません。 多くの計算資源を投入し、複雑なエージェントアーキテクチャを探索してもそこまでインパクトはないようにも見えます。
他にもメモリを活用した結果の精度向上幅を示している論文を見ます。
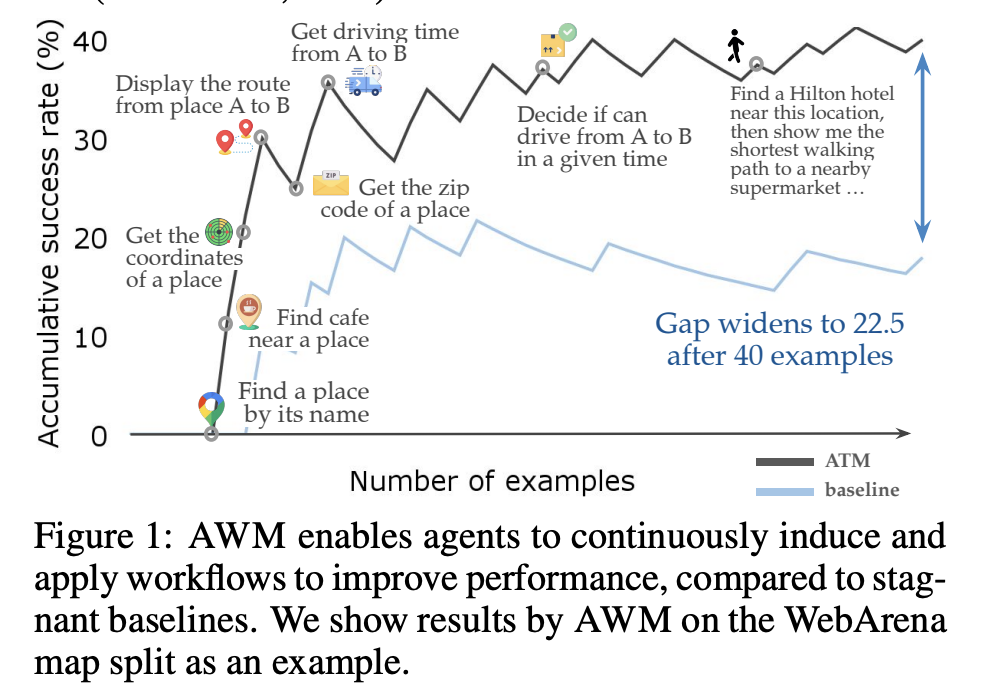
結論を出すのはまだ時期早々かと思いますが、現状だと同じLLMをベースにするとエージェントアーキテクチャに細部までこだわっても性能の改善は横並びか数%の違いで、メモリを使っても継続的に精度が向上しない可能性があり、ベースのLLMの性能アップの影響が大きいと考えます。 正当にエージェントの細部にこだわっても精度が一定以上超えないのは、エージェントの内部でよくあるLLMの能力の限界にぶつかっているからです。 例えば、長期計画が苦手とか、環境の適応力がないとか、Weekly AI Agent News!を読んでいる人なら分かると思います。 ベンチマークは意図して簡単なタスクから難しいタスクがあるので精度が出なくても仕方ありません。 ビジネスではエージェント内部でLLMの能力の限界にギリぶつからない範囲で価値を出しましょう。
エージェントのタスク成功率を高める技術要素は何だろう
以降は私のただの考えです。エビデンスがあるわけでもないです。 今までの機械学習はざっくりデータ、モデル、ハイパラが予測モデルを作る要素でした。 特に“Garbage in , Garbage out”と言われるようにデータの品質が重視され、モデルは初手これだよねというベースモデルが確立されて、あとはハイパラ最適化の世界でした。データが大事と良く語っていたと思います。 今のエージェントはクローズドモデルのLLMの土台があって、環境から観測できることを設計し、エージェントのアーキテクチャを設計し、プロンプトチューニングをおこない、メモリを活用します。
エージェントの場合、精度改善に強く寄与するのはどの要素なのでしょうか。
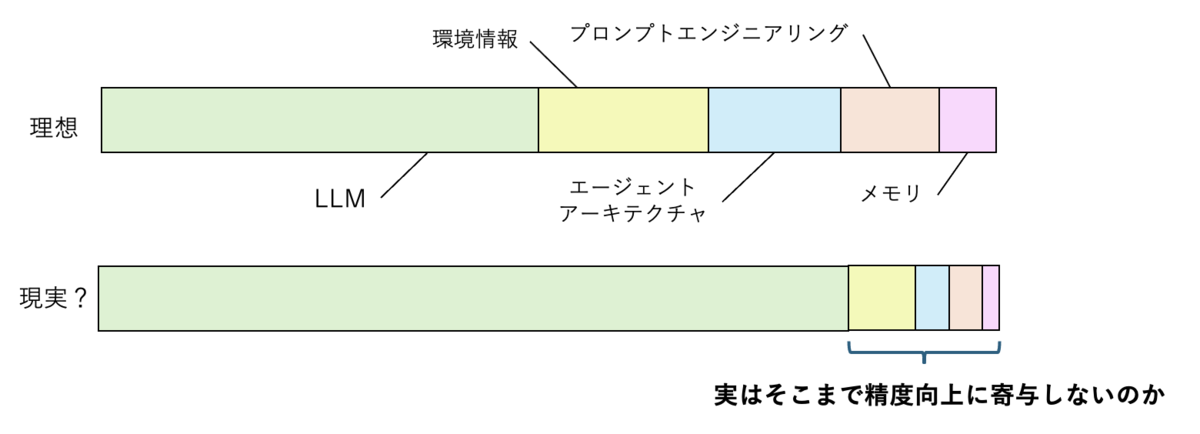
下段のグラフも仮説ですが、自分の感じているところです。 エージェントはLLMの能力に強く依存しており、正当に作り込んだエージェントアーキテクチャとプロンプトであれば、アーキテクチャバイアスはあれど、最終的な精度に影響は小さいのではないかというものです。 Webナビゲーションなどデジタルエージェントに関しては、どのエージェントも工夫は違えど精度が似たり寄ったりな部分で、乱暴に言えば、ベースのLLMの差が最も影響するのではないかと考えています。 そのLLMの差も段々と小さくなってきていますが。。。
私はよくLLM+αと比べ、エージェントにすることで最終回答の品質ってどのくらい良くなるの?と言います。なぜ良くなったのかも言語化させます。ツールを使うことでしか解けないタスクならば、シンプルなエージェントと比較して意味があるのかを考えます。みんさんの体感はどうでしょうか。エージェントのどの要素を改善していくことが必要だと思いますか。
機械学習のパラダイムにエージェントを照らし合わせて考える
精度改善の貢献度を考えるためにエージェントを機械学習のパラダイムに重ねると、モデルがLLMとエージェントアーキテクチャで、ハイパラがプロンプトになり、データが環境情報(APIレスポンス内容、ドキュメント、コード生成で利用できるライブラリなど)とメモリ(対話履歴や行動履歴)ということになるのでしょうか。 そう考えると、私の中ではモデルに該当する部分はすぐ固定化されてきて、ハイパラやデータの部分で工夫をすることになるのではないかと予想します。 補足ですが、私と似たような考えで、学習のパラダイムに則りプロンプトやツール最適化を行う研究はあります (Zhang, 2024), (Zhou, 2024)。
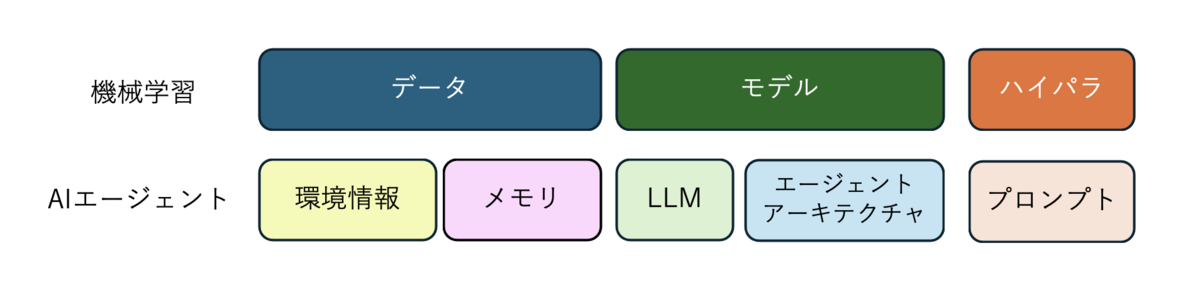
どうやってエージェントの精度を高めるのか考えてみる
もしエージェントアーキテクチャの貢献度が高くないのなら、既存研究のアーキテクチャを模倣して、環境から得られる情報の質を高めたり、メモリの工夫をしたり、プロンプトの工夫にこだわってもいいのかもしれません。 ただし、プロンプトはLLMに依存するので、モデルのバージョンが変わるたびに調整が必要になります。 また、環境情報をいじりすぎると他のエージェントとの比較が大変になります。ビジネスでは関係ないのでガンガン環境情報の質を高めましょう。
メモリに関しては、WebアプリChatGPTの対話セッションログとは完全に分けて考えて、必要な情報を適切な形式で再利用性を高めて蓄積しましょう。
最後に学習による性能特化は重要です。ソフトウェアエージェントのDevinではo1-previewが出たときに早期アクセスして評価していました。その結果です。
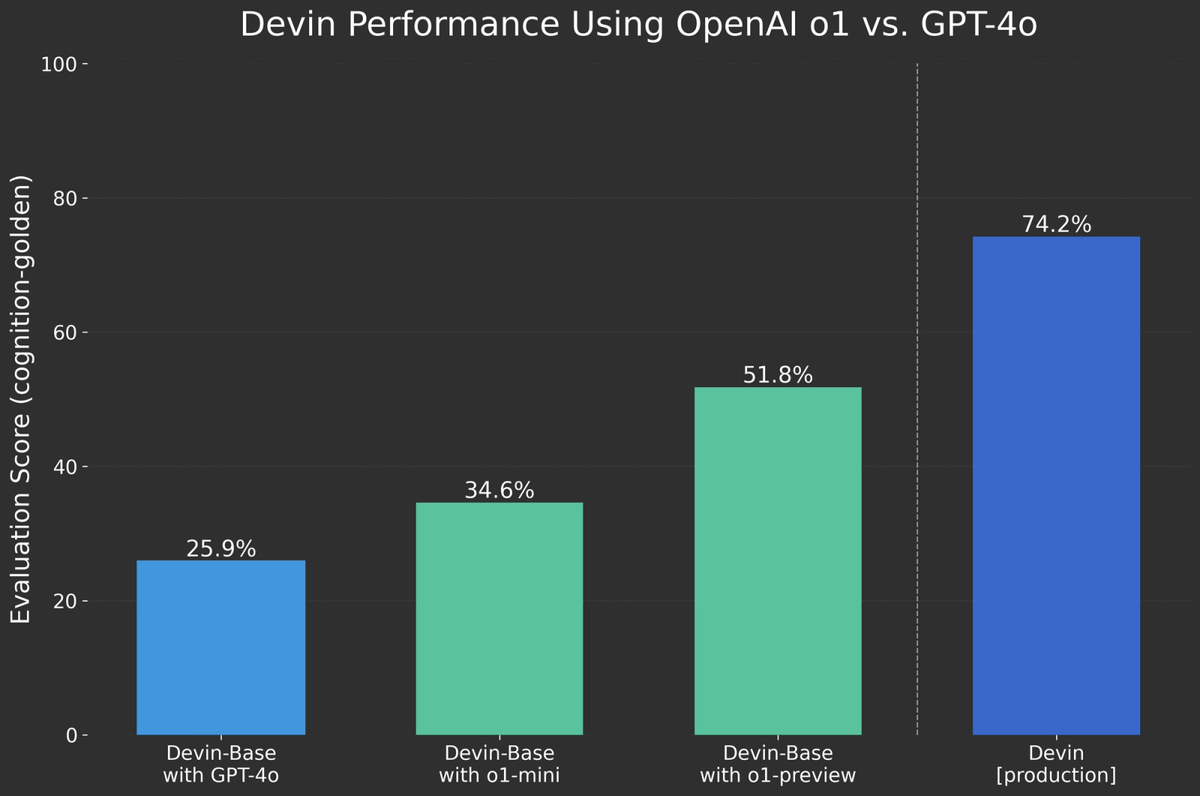
Devinの社内評価ベンチマークで性能がgpt-4oからo1-previewにすることで2倍の51.8%にも上がっています。 そして、モデルを独自データで事後学習した製品用のDevinは更にその上をいく74.2%です。 ここからもモデルを変えることが重要であり、特定の用途で学習をすると精度が格段に向上することが分かります。
更新し続けて良かったこと3選
応用領域や研究アイデアは業務に還元できる
これは非常に大きかったです。 エージェントの議論を社内でするとき、取り組む題材の選定や業務課題を技術に落とし込むときに研究アイデアやテクニックは参考になりました。 あの論文の方法は試してみてもいいな〜と思うことができるようになりました。初手でいきなり筋の悪い一手を打たなくなったと思います。 また、エージェントで取り組むべきかの判断も鋭くなったと思います。どうしてもマーケティング用語から自動化したいならエージェントという方向で考えがちですがそれは間違いです。 エージェントに適した問題設定でないと、無駄な労力をかけるだけです。その目利きは鍛えられたと思います。
会社メンバーの基礎体力の底上げになる
社内育成においてもエージェントの公開資料と合わせて説明することで全員の知識が高まったと思います。 タスク振りも私のイメージしている方法と近い論文をWeeklyの中からささっと選んで共有することで立ち上げもスムーズに思えました。 開発をするときにエンジニアとリサーチャーで知識の差があるとプロダクトで失敗します。相互に意見を合わせて情報交換することで会議や会話が円滑になりました。
イベントや会社外の方との交流が増えた
最初の数ヶ月は認知のために定期的に更新する度に発信をしていました。 ある程度、読者層がついたところで更新の有無をXで通知はしなくなりましたが、それでも勝手に拡散され読者層は一定数いるように思います。 その認知活動の中で、エージェントを取り組む同士やイベントの登壇依頼などが来て外部でも知人が増えました。
最後に
この記事で伝えたいのは、安心してくださいエージェントのアーキテクチャはどれも似ています。 ただし、エージェントの細部にこだわることを忘れてはいけません。
エージェントの応用は今年のトレンドでした。 来年も自社の強みを活かす形でエージェントによる業務効率化を目指しましょう。 どの会社でもできそうなことは別の誰かに任せましょう。
私は正当に作り込んだエージェントであれば、途中でよくあるエージェントの課題(エージェント内部のLLMの課題)にぶつかり、アーキテクチャやプロンプトをそれ以上いじっても精度は対して変わらないラインに達すると考えています。 まずはそこまで作り込めるエージェント開発者になりましょう。 そのためにも作り込めそうなポイントを押さえましょう。 そしてビジネスではエージェントの課題にぶつからない範囲で価値を創出しましょう。 あとはLLMの性能が向上することを期待しましょう。
Weekly AI Agent News!を更新し続け、学び続けるととても視野も広がりましたし、専門性もつきました。 ぜひ、学生の方も今のうちに突き詰めたいことは突き詰めて発信してくださいね!
最後まで読んでいただき、ありがとうございます!
おまけ)最近のAIに関する情報キャッチアップについて思うこと
最新の生成AIの論文は毎日出ていますが、それを全て追っかけると追いかけることが目的になり、企業価値を高めるような仕事なんてできません。 嬉しいことにXでは海外の方含めて国内の方でも論文の要約を発信される方が増えています。その情報を頼るのは一つ有効かも知れません。 ただ嬉しい弊害で、毎朝論文の情報が流れてきて、追いかける情報が増え、自社はまだ全然できていない、社会から遅れていると不安に駆られる方もいるかも知れません。
個人的に木ばかりを見て森を見ないのはナンセンスだと思っています。 エージェントに限らず、生成AIの動向を抽象化して点と点を線で結ぶように解釈することで、驚きが減り冷静に差分を見れます。 特定の文脈で「あることが発見された!」「〜が自動化された!」という論文だけで鵜呑みにするのは危険です。 同じ主張をする論文が多く出てくればそれは信頼できる知見ですが、そうでない場合は一旦頭の片隅に入れておく程度で良いです。
私は生成AIでもエージェントに関する論文に絞り、週単位や月単位でグループ化してまとめているのは、そういう点と点を線で結びやすくするためです。 私は来年もエージェントを本当に業務適応できるか、価値があるのかを取り組む予定なので、AIエージェント周りの動向はWeekly AI Agent News!を通して伝えていきます。